
CheerUp_Cheers
데이터베이스 본문
#질문
[데이터베이스]
- 키의 종류와 개념 설명.
- 데이터베이스 정규화 설명, 왜 하고 어떻게 하는지, 그리고 역정 규화는 무엇인지. 왜 하냐?.왜하냐?
- 데이터 이상이란?
- 데이터베이스 트랜잭션(COMMIT,ROLLBACK)에 대하여 설명, ACID에 대해 설명
- 데이터베이스 무결성에 대하여 설명
- NoSQL과 SQL(RDMS)가 뭔지 설명
- CAP이론
- Data Independecy란?
- Trigger의 역할
- Join의 종류와 아는 대로 설명
- index? index를 쓰는 이유와 장단점.
- 고립성의 4가지 고립 레벨(트랜잭션 격리 수준)
- 데이터베이스 팬텀 리드란??
- NULL이란?
- Redis
-
*키의 종류와 개념 설명.
- 후보키
튜플을 유일하게 식별하기 위해 사용하는 기본키로 사용 가능한 부분집합.
유일성(하나의 킷값으로 하나의 튜플만을 식별), 최소성(꼭필요한속성만)
- 기본키
후보키 중 선택된 키, NULL을 가질 수 없다.(개체 무결성)
- 대체키
기본키를 제외한 후보키(=보조키)
- 슈퍼키
최소성을 만족하지 못하지만 튜플에 대한 유일성은 만족
- 외래키
R1,R2R1, R2의 관계에 R1이 참조하는 R2의 기본키와 같은 속성.
-
*데이터베이스 정규화 설명, 왜 하고 어떻게 하는지, 그리고 역정 규화는 무엇인지. 왜 하냐?.왜하냐?
#정규화
논리적 데이터베이스 설계에 있어서 테이블 구조화하는 기법 중 하나.
(도 부 이 결 다 조)
1 - 도메인이 모두 원자값으로 구성되어있다.
2 - 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속.
3 - 기본키가 아닌 모든 속성이 기본키에 이행적 함수 종속이 아니다.
BCNF - 모든 결정자가 후보키KEY인 경우.
4 - 다치 종속 제거
5 - 결합종속(join dependency)을 분리한 것, 조인종속이 후보키를 통해서만 성립.
다치 종속(MVD: Multi Valued Dependency)
A, B, C 세 개의 속성을 가진 릴레이션 R에서 어떤 복합 속성(A, C)에 대응하는 B 값의 집합이 A 종속되고 C 값에는 무관할 때 다치 종속 R-A ->-> R-B 이 존재한다.
조인 종속(JD: Join Dependency)
어떤 릴레이션 R이 자신의 Projection(X, Y, ..., Z)에 대한 조인의 결과가 자신과 같을 때 조인 종속(JD)(X, Y, ..., Z)은 R의 속성 집합의 부분집합입니다.
#왜하냐?
안정적인 자료구조 변환.
- 데이터 이상현상(삽입 이상, 변경이상,삭제이상)
- 데이터 중복 현상을 방지
#역정규화?
조인을 하면 성능이 엄청 떨어짐(조회).
데이터 이상현상과 중복 현상과 성능에 적절한 정규화가 필요.
-
*데이터베이스 트랜잭션에 (Commit, Rollback)대하여 설명, ACID에 대해 설명
#트랜잭션이란?
데이터베이스 상태를 변환시키는 한 번에 실행되야할 논리적 작업 단위..
#트랜잭션 연산 및 상태
- Commit
한개의 트랜잭션에 대한 작업이 성공적으로 끝났고, 갱신연산이 완료된것을 관리자에게 알려주는 연산
- RollBack
하나의 트랜잭션 처리가 비정상적으로 종료, 일부가 정상적이더라도 일관성과 원자성을 위해 연산 취소(Undo)
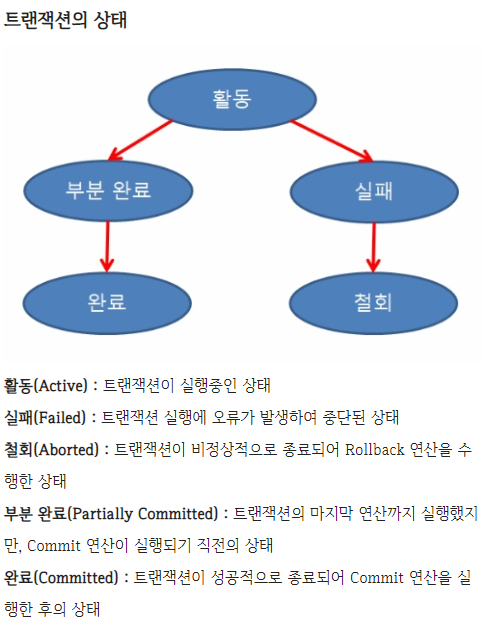
#ACID
- 원자성, 트랜잭션 연산은 데이터베이스에 모두 반영되든지 전혀 안 되던지..
- 일관성, 트랜잭션의 성공적 실행은 언제나 일관성 있는 데이터베이스 유지.
- 격리성, 둘 이상 트랜잭션이 동시에 병행, 다른 트랜잭션에 끼어들 수 없음..
- 영속성, 성공적으로 완료된 트랜잭션 결과는 영구 반영..
-
*데이터베이스 무결성에 대하여 설명
#무결성이란
데이터베이스의 저장된 값과 현실세계의 실제값의 일치하는 정확성.
#종류
도메인 무결성 – 특정 속성 값이, 그 속성의 도메인에 속한 값이여야함..
개체 무결성 – 릴레이션의 기본키를 구성하는 속성은 NULL이나 중복 불가
참조 무결성 – 외래키값은 NULL이거나 참조 R의 기본키와 동일해야 함, 즉 참조할수 없는 외래키값 못가짐.
-
*NoSQL과 SQL(RDMS)가 뭔지 설명
#NoSQL
- 스키마가 없음, 데이터 관계와 정해진 규격이 없다.( = Join이 불가.)
- 인터넷의 발달로 대규모의 데이터 혹은 비정형 데이터의 처리.
-> 분산처리(수평적 확장) 기능을 쉽게 제공.
- 가용성을 위한 데이터 복제 등의 RDBMS가 지원 못하는 것 지원
- 최초 테이블 생성 시 데이터 간의 관계 정의(x)
->빠른 설계, 큰 용량, 데이터 분산(x)
#NOSQL 단점
복잡한 조인 어려움, 일관성이 항상 보장 안됨(lock사용 안 해서)
데이터 중복을 계쏙 업데이트
유연성으로 인한 데이터 구조결정을 미룰수도있음
ex)몽고디비
#NOSQL 장점
모든 서버를 업데이트하기 전에 locklock을 걸어 못 읽게-> 일관성
상호 관련성이 있는 테이블의 집합.
스키마가 없어서 유연함, 언제든지 저장된 데이터 조정과 필드 추가.
데이터는 앱이 필요로하는 형식으로 저장되어, 데이터 읽는 속도가 빠름
#NOSQL 언대써
데이터의 구조를 정확히 알수 없거나, 변경 확장이 잦음
자주 읽지만 변경이 자주없으면
#SQL
RDMBS에서 데이터 저장,수정,삭제 및 검색
- RDMBS
1) 데이터는 정해진 데이터 스키마에 따라 테이블 저장(무조건 스키마 준수)
2) 테이터는 관계(데이터 중복피함)를 통해 여러테이블에 분산
#SQL 장점
명확한 스키마, 데이터 무결성
관계는 각데이터 중복없이 한번만 저장
#SQL 단점
덜유연 -> 데이터 스키마의 사전 계획(수정어려움)
#SQL 언대써
명확한 스키마가 사용자와 데이터에게 중요할 경우
관계를 맺고있는 데이터가 자주 변경될 경우
-
*CAP 이론
다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터 보장.
#C(일관성)
느슨한 처리되는 일관성(데이터 저장 결과를 클라이언트에 응답하기 전,, 모든 노드에 데이터를 저장하는 동기 법.. 메모리나 임시파일에 기록하고 클라이언트에게 응답을 보인 후,, 특정 이벤트 후로 프로세스를 사용하여 데이터를 동기화하는 비동기식 방법)
#A(가용성)
내고장성(내고장성(읽시 쓰기 요청)의 항상 응답, NoSQL은 클러스터 내에서 몇 개의 노드가 고장 나더라도 정상적인 서비스 가능. 데이터복제(데이터 복제(다중노드에 중복 저장)를) 통해.
#P(네트워크 분할 허용성)
지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서 두 지역 간의 네트워크가 단절되거나 데이터 유실이 일어나도 각 지역 시스템은 정상적 동작.
-
*Data Independecy란?
자료의 독립성 – 어느 단계의 스키마를 바꾸었을 때, 그위 단계의 스키마에 영향을 주지 않고, 응용프로그램에 영향 안주는 것.
종류 – 물리적 자료 독립성(물리적 스키마 바꿔도 논리적 스키마 영향 X)X)
논리적 자료 독립성(논리적 스키마 바꿔도 뷰 단계의 스키마 영향 X)X)
데이터스키마 – 자료의 구조, 표현방법, 자료 간의 관계를 나타내는 메타데이터.
-
*Trigger의 역할
트리거란 테이블에 조작이 가해졌을 시, 미리 지정한 처리를 자동으로 시키는 블록.
-
*Join의 종류와 아는 대로 설명
1)이너조인(교집합1) 이너 조인(교집합) - 중복된 값 출력
2)아우터조인
LEFT 아우터 조인 – 왼쪽 테이블로 JOIN하겠다.(AJOIN 하겠다.(A테이블의 전체 데이터와 중복 데이터))
FULL 아우터 조인 – 합집합. 기준 테이블 의미 없음..
3)크로스조인 – 모든 경우의 수를 표현, A(3) B(4) 면면 12개의 데이터 검색.
4)셀프조인 – 자기 자신과 조인, 자신의 칼럼을 변형시켜 활용 시 사용.
-
*index? index를 쓰는 이유와 장단점.
#인덱스
DBDB 성능 향상, 적절한사용.
Table의 컬럼을 색인화(따로 파일 저장) -> Table을 Full Scan하지 않아~
#장점
- 검색 속도 향상되는 편(특정 행 가져올 때)
- 부하가 줄고 성능 높임.
#단점
- DB의 10% 정도의 공간 요구
- 인덱스 생성시간 요구
- 변경(삽입,삭제,변경) 작업 多-> 성능하락
-
고립성의 4가지 고립 레벨(트랜잭션 격리 수준)
#선택시 고려
동시성 증가 -> 데이터 무결성 문제
데이터 무결성 유지 -> 동시성 떨어짐
레벨 높을수록 발생 비용 증가.
1) Read Uncommitted
commit 안 한 것도 트랜잭션이 읽는걸 허용.
DirtRead – 확정(Not committed)안한 값을 읽음.
2) Read committed
commit 이 이루어진 트랜잭션만 조회 가능.
SQL서버의 Defulat로 사용하는 레벨.
Non-Repetable Read – 중간에 업데이트 시, 그전과 후과 결과가 다름..
3) Repetable Read
자신보다 늦게 시작한 트랜잭션이라면 commit됐더라도 그전 결과 참조.
팬텀리드 – 이 제약을 받지 않는INSERT쿼리로 갑자기 없던 데이터가 나와서 읽힘
4) Serializable
가장 높은 격리 수준
다른 사용자의 트랜잭션 영역에 해당되는 데이터의 수정 및 일기 불가.
lock 까다롭고 성능 하락

-
NULL이란?
- 아직 알려지지 않았거나.
- 모르는 값(해당 없음)
- 정보의 부재(아무것도 없음)
- 0또는 공백은 절대 아님!
- NULL + 값 = NULL
->따라서 RDBMS에서는 NVL()을 통해 숫자로 바꾼뒤 연산을 가능케함.
-
Redis
- 정의
빠른 오픈 소스 인 메모리 키 값 데이터 구조 스토어
보통 데이터 베이스는 하드디스크나 SSD에 저장.
Redis는 메모리(ram)에 저장하여 디스크 스캐닝이 필요 없어 매우 빠름
- 램은 휘발성! 껐다키면 날아가는데?
백업 과정이 있음.
1) snapshot : 특정 지점을 설정하고 디스크에 백업
2) AOF(Append Only File) : 명령(쿼리)를 저장하고, 서버 셧다운시 재실행해 다시 만들어 놓는것.
- 구조
key/value 값(비정형 데이터를 저장하는 비관계형 데이터베이스 관리 시스템)
value는 5가지 가능
1)String
2)set
3)sorted set
4)Hash
5)List

