
CheerUp_Cheers
아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (2) 본문
EC2
SSH 접속
인스턴스 퍼블릭 IPv4 주소
## 접속 ssh -i "{pem 키 경로}" ec2-user@{퍼블릭 IPv4 DNS}탄력적 IP 할당
인스턴스를 재시동해도 IP가 변경되지 않는다.
ssh -i "{pem 키 경로}" ec2-user@{발급받은 탄력적 IP}
자바
설치
카프카 브로커는 스칼라와 자바로 작성되어 JVM 환경 위에서 실행.
// 설치 sudo dnf install -y java-1.8.0-amazon-corretto-devel // 버전 확인 java -version
카프카
설치
// brew brew install wget // 가져오기 wget https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgz // 압축 풀기 tar xvf kafka_2.12-2.5.0.tgz
카프카 브로커 힙 메모리 설정
환경변수 설정하기
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m" echo $KAFKA_HEAP_OPTS→ 환경 변수는 터미널 세션이 종료되고 나면 초기화 됨으로 ~/.bashrc 파일을 수정해 쉘이 실행될때마다 반복적 구동 추가
bashrc 수정하기
$ vi ~/.bashrc export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m" $ source ~/.bashrc브로커 실행 시, 메모리 설정 부분
기본 Xmx 1G, Xms 1G
파일 : kafka-sever-start.sh
카프카 브로커 실행 옵션 설정
config/server.properties
브로커의 클러스터 운영에 필요한 옵션
실습용 카프카 브로커만 실행
advertiesed.listener만 설정.
카프카 기본 포트
IP - 퍼블 IPv4값 (탄력적 주소는 안되고 내부면 프라이빗만)
PORT - 카프카 기본포트 :9092
advertised.listeners=PLAINTEXT://{프라이빗 IPv4}:9092설정 변경시, 브로커 재시작 필요
그외 설정
카프카 번호
카프카 브로커 통신을 위해 열어둘 인터페이스 IP, PORT
SASL_SSL, SASL_PLAIN 보안 설정 프로토콜 매핑
네트워크 스레드
브로커 내부 스레드
통신을 통해 가져온 데이터 파일 저장할 디렉토리
파티션 개수
브로커가 저장한 파일의 삭제까지의 시간
추천값은 log.retention.ms이며 -1 기입시 영원히 삭제하지않음.
저장할 파일의 최대 크기
넘으면 새로 파일 생성
파일 삭제의 주기
카프카 브로커와 연동할 주키퍼의 IP와 port 설정
주키퍼와 카프카 브로커를 동시 실행함으로 localhost:2181
주키포의 세션 타임아웃 시간 지정
주키퍼 실행
주키퍼 역할
- 메타데이터 관리: 토픽, 파티션, 브로커 정보 등 클러스터 상태 저장.
- 리더 선출: 브로커 간 장애 발생 시 리더 브로커를 선출.
- 클러스터 상태 모니터링: 브로커가 정상인지 감지
백그라운드 실행
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties실행 확인
jps -vm실제 환경
실제 운영환경에서는 3대이상의 서버 필요.
카프카 브로커 실행
백그라운드 실행
bin/kafka-server-start.sh -daemon config/server.properties
로컬 컴퓨터에서 카프카와 통신 확인
카프카 바이너리 패키지 다운로드
카프카 브로커에 대한 정보를 가져올 수 있는 명령어 제공.
curl https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgz --output kafka.tgz tar -xvf kafka.tgz원격으로 버전확인하기
카프카 버전, broker.id, rack 정보, 각종 브로커 옵션 확인 가능
bin/kafka-broker-api-versions.sh --bootstrap-server {프라이빗 IPv4}:9092
카프카 커맨드 라인 툴
기본
카프카 명령어에는 필수 옵션과 선택옵션
선택옵션
브로커에 설정된 기본 설정값 또는 커맨드 라인 툴의 기본값 대체
필요성
토픽이나 파티션 개수 변경과 같은 명령을 실행해야하는 경우가 생김.
kafka-topics.sh
설명
토픽 관련 명령 실행.
토픽 관련 파티션은 최소 1개
한번에 처리할 수 있는 데이터 양을 늘릴 수 있음.
→ 토픽 내부에서도 파티션을 통해 데이터 종류를 나누어 처리 가능
토픽 생성
커맨드 라인 툴로 토픽을 명시적으로 생성
왜?
데이터의 특성에 따라 다르게 처리.- 동시 데이터 처리량이많아야 하는 경우 파티션 개수 100개
- 단기간 데이터 처리 시에는 보관기간 옵션을 짧게
kafka-topics.sh 명령어
bin/kafka-topics.sh \ --create \ --bootstrap-server my-kafka:9092 \ --topic hello.kafkabin/kafka-topics.sh \ --create \ --bootstrap-server my-kafka:9092 \ --partitions 3 \ --replication-factor 1 \ --config retention.ms=172800000 \ --topic hello.kafka.2파티션 개수, 복제 개수 등 다양한 옵션으로 지정한것.
replication-facotr
실제 카프카 브로커에 복제를 할 개수이며 실제 업무환경에서는 3개이상.
명시하지 않았으면 브로커 설정의 default.replication.factor 옵션 수정
config
명령에 포함되지 않은 추가적 설정
retention.ms는 토픽의 데이터 유지 기간
토픽 생성시 -zookeeper대신 —bootstrap-server를 쓰는 이유?
2.1을 포함한 이전 버전은 주키퍼와 직접 통신하여 명령함.
2.2버전 이후로는 주키퍼와 통신을 하는 대신 카프카와 통신하여 복잡도를 줄임
토픽 리스트 조회
토픽 리스트 조회
bin/kafka-topics.sh --bootstrap-server my-kafka:9092 --list
토픽 상세 조회
bin/kafka-topics.sh --bootstrap-server my-kafka:9092 --describe --topic hello.kafka.2
토픽 옵션 수정
파티션 개수 변경
kafka-topcis.sh
## 파티션 개수 변경 bin/kafka-topics.sh --bootstrap-server my-kafka:9092 \ --topic hello.kafka \ --alter \ --partitions 4 ## 조회 bin/kafka-topics.sh --bootstrap-server my-kafka:9092 \ --describe \ --topic hello.kafka토픽 삭제 정복 리텐션 변경
kafka-configs.sh
## 파티션 개수 변경 bin/kafka-configs.sh --bootstrap-server my-kafka:9092 \ --entity-type topics \ --entity-name hello.kafka \ --alter --add-config retention.ms=86400000 ## 조회 bin/kafka-configs.sh --bootstrap-server my-kafka:9092 \ --entity-type topics \ --entity-name hello.kafka \ --describe
kafka-console-producer.sh
생성된 토픽에 데이터를 넣을 수 있는 명령어.
레코드
토픽에 넣는 데이터로 메시지 키(key)와 메시지 값(value)로 이루어짐.
메시지 키 없이 메시지 값만 보내기
bin/kafka-console-producer.sh --bootstrap-server my-kafka:9092 \ --topic hello.kafka ## 메시지 입력 >hello >kafka >0 >1 >2 >3UTF-8기반 ByteArraySerializer로만 직렬화
→ 카프카 프로듀서 애플리케이션을 직접 개발
메시지 키를 가지는 레코드 보내기
bin/kafka-console-producer.sh --bootstrap-server my-kafka:9092 \ --topic hello.kafka \ --property "parse.key=true" \ --property "key.separator=:" ## 메시지 입력 >key1:no1 >key2:no2 >key3:no3parse.key=true
레코드 전송시 메시지 키 추가
key.separator=:
‘:’ 를 메시지 키와 메시지 값을 구분하는 구분자로 선언.
디폴트는 \t, 구분자없이 등록시 종료(이전 값은 정상 요청)
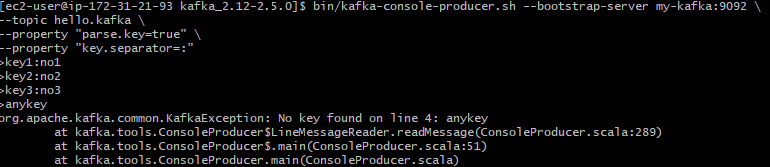
kafka-console-producer.sh
토픽으로 전달 했던 값은 어떻게 되었을까.. 하고 미리 찾아서 확인은 했었지만 바로 다음 파트에 나온다.
토픽 기준 처음 부터 전송한 데이터 읽기
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \ --topic hello.kafka \ --from-beginningfrom-biginning
처음부터 끝까지 읽는다는 옵션
메시지키와 메시지값을 확인
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \ --topic hello.kafka \ --property print.key=true \ --property key.separator="-" \ --group hello-group \ --from-beginning여러 파티션으로 데이터의 순서는 다르게 나옴.
→ 하나의 파티션으로 하는게 순서 보장
—group
신규 컨슈머 그룹 생성.
컨슈머 그룹을 통해서 가져간 메시지에 대해 커밋을 남김.
커밋
컨슈머가 특정 레코드까지 처리를 완료했다고 오프셋 번호를 브로커가 저장하는것
kafka-consumer-groups.sh
생성된 컨슈머 그룹의 리스트 확인
bin/kafka-consumer-groups.sh --bootstrap-server my-kafka:9092 --list컨슈머 그룹의 토픽 확인하기
bin/kafka-consumer-groups.sh --bootstrap-server my-kafka:9092 \ --group hello-group \ --describe
설정
GROUP, TOPIC, PARTITION
마지막으로 커밋한 토픽과 파티션.
CURRENT-OFFSET
토픽의 파티션에 가장 최신 오프셋
LOG-END-OFFSET
어느 오프셋까지 커밋했는지
LAG
지연 발생 정도
(LOG-END-OFFSET) - (CURRENT-OFFSET)
→ 전달속도에 비해 컨슈머의 처리량이 느리다
kafka-verifiable-producer, Consumer.sh
String 타입의 메시지 값을 코드없이 주고 받아볼수 있음
간단한 네트워크 통신 테스트
메시지 보내기
bin/kafka-verifiable-producer.sh --bootstrap-server my-kafka:9092 \ --max-message 10 \ --topic verify-testmax-message
-1로 설정시 종료될때까지 토픽으로 보냄
메시지 확인
bin/kafka-verifiable-consumer.sh --bootstrap-server my-kafka:9092 \ --topic verify-test \ --group-id test-groupgroup-id
컨슈머 그룹 지정
메시지 보냄과 확인 화면
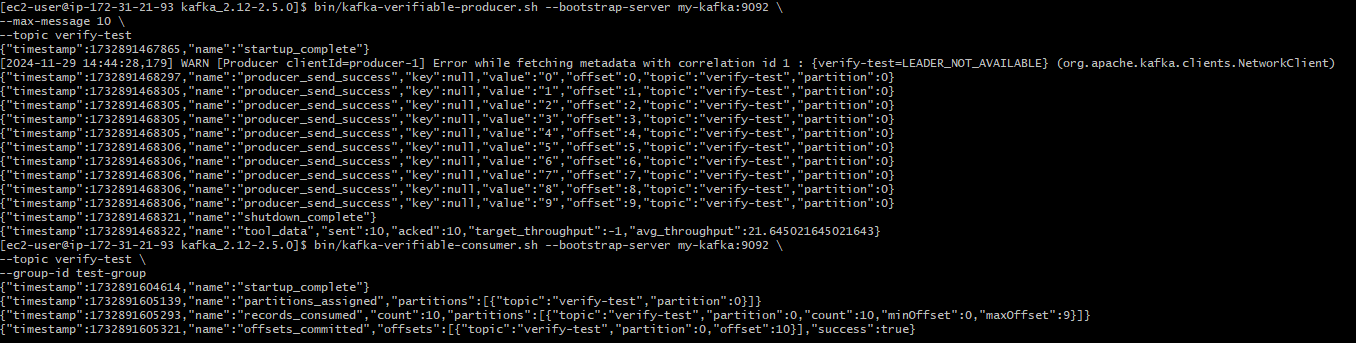
kafka-delete-records.sh
적재된 토픽 지우기.
토픽의 오래된 오프셋 부터 지우기
삭제할 토픽정보 기입
vi delete-topic.json {"partitions": [{"topic": "test", "partition":0, "offset":50}], "version":1}offset
오프셋 이전의 데이터를 모두 삭제함.
특정범위 삭제를 원하면 옮긴 뒤 기존 토픽삭제하라고..
삭제
bin/kafka-delete-records.sh --bootstrap-server my-kafka:9092 \ --offset-json-file delete-topic.json
'미들웨어' 카테고리의 다른 글
| 아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (4) (1) | 2025.01.12 |
|---|---|
| 아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (3) (0) | 2024.12.23 |
| 아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (1) (0) | 2024.11.24 |
| 메시지 큐 차이 (Redis Queue, Kafka, RabbitMQ) (0) | 2024.11.10 |

