
CheerUp_Cheers
아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (3) 본문
Chapter3
3.1 카프카 브로커,클러스터,주키퍼
데이터 저장/전송
실습한 저장된 파일 시스템 확인
config/server.properties의 log.dif 옵션에 정의한 디렉토리
ls /tmp/kafka-logs파티션 수만큼 생성된 디렉토리 확인

토픽의 0번 파티션에 존재하는 데이터

용어
log - 메시지와 메타테이터
index - 메시지의 오프셋
timeindex - 메시지에 포함된 timestamp값을 기준으로 인덱싱한 정보, 브로커가 적재한 데이터 삭제나 압축
카프카는 파일 시스템에 저장한다.
느려지지 않는가?
파일 입출력에대한 속도 이슈가있지만, 페이지 캐시 사용으로 디스크 입출력 속도를 높여서 문제 해결.→ 브로커의 힙메모리를 크게 설정할 필요가 없다.
데이터 복제, 싱크
복제 단위
파티션 단위로 이루어지며, 토픽 생성시 옵션을 선택하지않으면 브로커 설정을 따라감.
리더/팔로워 파티션
팔로워(복제) 파티션은 리더 파티션의 오프셋을 확인하여 차이나는 경우 저장(복제)
단점
복제 개수 만큼 저장 용량이 늘어남
복제 개수
1개 or 2개 : 데이터 처리 속도가 중요하다
3개이상 : 정보 유실이 일어나면 안된다
컨트롤러
클러스터의 다수 브로커중 한대가 컨트롤러 역할.
브로커 상태가 안좋으면 클러스터에서 빼내는 역할.
데이터 삭제
로그 세그먼트
카프카의 삭제되는 파일 단위
카프카는 다른 메시징 플랫폼과 다르게 컨슈머가 가져가도 삭제하지 않음.
삭제하지 않고, 메시지 키를 기준으로 압축하는 정책을 가져갈 수 도 있음.
컨슈머 오프셋 저장
위치
아래의 저장된 기준으로 레코드를 가져가서 처리.
ls /tmp/kafka-logs/__consumer_offsets
코디네이터
클러스트의 다수 브로커 중, 한대가 역할을 수행.
리밸런싱
컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 배분
주키퍼의 역할
카프카의 메타 데이터를 관리하는데 사용.
주키퍼는 카프카 2.8부터는 사용하지 않음.
카프카 서버에 주키퍼 붙이기
2181포트가 주키퍼 포트
bin/zookeeper-shell.sh my-kafka:2181주키퍼 명령어

ls /
root znode의 하위 znode확인
get brokers/ids/0
실승용으로 생성한 카프카 브로커에 대한 정보
get /controller
어느 브로커가 컨트롤러인지
get /brokers/topics
저장된 토픽 확인
주키퍼에서 다수의 카프카 클러스트를 사용하는 방법
주키퍼의 서로다른 znode에 카프카 클러스터들을 설정하면 됨.
주키퍼 옵션 정의
파이프라인용 카프카 클러스터 : zookeeper.connect=localhost:2181/pipeline 실시간 추천용 카프카 클러스터 : zookepper.connect=localhost:2181/recommend
3.2 토픽과 파티션
레코드
파티션에 들어가는 프로듀서들이 보낸 데이터
속도 증가
파티션과 컨슈머 개수를 늘려서 처리량(병렬처리) 가능
큐와 비슷한 구조
토픽 이름 제약 조건
길이제한, 빈문자열 지원하지 않음 등.. 이 있으니 토픽 생성시 확인하여 생성하면 될듯하다.
의미있는 토픽 작명
<환경>.<팀명>.<애플레킹션명>.<메시지-타입>
prd.marketing-team.sms-platform.json<프로젝트-명>.<서비스-명>.<환경>.<이벤트-명>
commerce.payment.prd.notification
… 등 팀 혹은 사내 정책으로 정하면 좋을 듯하다.3.3 레코드
레코드 구성
타임스탬프, 메시지 키, 메시지 값, 오프셋, 헤더
레코드 수정
수정은 불가능하며, 로그 리텐션 기간 또는 용량에 따라 삭제만.
타임스탬프
프로듀서에서 생성된 시점의 유닉스 타임.
컨슈머는 언제 생성되었는지 확인은 가능하나, 프로듀서가 생성할떄 임의의 타임스탬프 값을 설정할 수있어 설정에 따라 다를 수 있다.
메시지키와 파티션 관계
프로듀서가 토픽에 레코드를 전송 할때, 메시지 키의 해시값을 토대로 파티션 지정.
→ 하지만, 파티션 개수가 변경되면, 매칭이 달라짐
메시지 값
브로커로 전송될때는 직렬화된 메시지 키와 값으로 전달.
컨슈머가 사용할때는, 동일하게 역직렬화 수행.
오프셋
오프셋은 지정할수 없고, 이전에 전송된 레코드의 오프셋 +1값.
헤더
레코드의 추가적인 정보를 담는 저장소 용도.
3.4 카프카 클라이언트
카프카 클라이언트
카프카 클러스터에 명령을 내리는 라이브러리.
프레임워크나 애플리케이션 위에서 동작
3.4.1 프로듀셔 API
프로듀셔 애플리케이션은 카픜에 필요한 데이터 선언.
브로커의 특정 토픽의 파티션에 전송.
데이터 전송
데이터를 직렬화하여 보내기 때문에, 자바의 선언 가능한 모든 형태를 브로커로 전송 가능.
토픽 생성
bin/kafka-topics.sh --bootstrap-server my-kafka:9092 --create \ --topic test \ --partitions 3프로듀셔 애플리케이션 메시지 발송
SimpleProducer실행.주의점
hosts 파일에 ec2설정과 같이 my-kafka를 퍼블릭 ip 로 설정
방화벽도 열어놔야함.
토픽 확인
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 --topic test --from-beginning파티셔너 종류
메시지키가 있을 경우, 키의 해시값과 파티션을 매칭하여 전송 동일
UniformStickyPartitioner
디폴트
RoundRobinPartitioner의 단점을 개선, 메시지키가없을때 최대한 동일하게 분배하는 로직 존재.
높은 처리량, 낮은 리소스 사용률
RoundRobinPartitioner
카프카 프로듀셔 압축옵션
기본적으로는 압축x
gzip, snappy, lz4, zstd 지원.
⇒ 네트워크 처리량에는 이득이지만, 컨슈머에서 처리해야함.
프로듀셔 주요 옵션
기본값을 잘 파악하여 설정하자!
필수옵션
bootstrap.servers
프로듀셔가 전송할 카프카 클러스터에 속한 브로커의 호스트 이름:포트 (2개 이상 입력하자)
key.serializer
value.serializer
선택옵션
acks
브로커들에 정상적으로 저장되었는지.
default : 1
- 0 : 브로커저장여부 안보고, 전송 즉시
- -1(all) : 토픽의 min.insync.replicas 개수에 해당하는 리더/팔로워 파티션에 저장되면 성공으로
- 1 : 리더파티션에 저장되면 성공으로
buffer.memory
브로커로 전송할 데이터를 배치로 모으기위해 설정할 버퍼 메모리양
default : 32MB
retries
프로듀셔가 브로커로 에러를 받고 재전송 횟수
default : 2147483647
batch.size
배치로 전송할 레코드 최대 용량.
너무 작으면 자주 보내어 네트워크 부담 ,너무 크면 메모리를 많이 사용.
default : 16384
linger.ms
배치를 전송하기전까지 시간
default : 0
partitioner.class
레코드를 파티션에 전송하기 위해 적용하는 클래스 지정
default : DefaultPartitioner
enable.idempotence
멱등성 프로듀서로 동작할지 여부. (Chapter4에서 배움)
default : false
transactional.id
프로듀서가 레코드 전송 시, 레코드를 트랜잭션 단위로 묶을지 여부 (설정 시, 트랜잭션 프로듀서로 동작)
default : null
메시지 키를 가진 데이터를 전송하는 프로듀셔
java -
ProducerWithKeyValueProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "Pangyo", "key");키랑 같이 console로 보기
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \ --topic test \ --property print.key=true \ --from-beginning
파티션 직접 지정
java -
ProducerExactPartitionProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, partitionNo, "key", "Pangyo");
커스텀 파티셔너 생성 및 설정
java -
ProducerWithCustomPartitionerCustomPartitioner는 키값을 확인하여 파티션 설정.
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);콘솔
--property print.partition=true 추가하면 어느 파티션에서 소비되었는지 확인가능
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \ --topic test \ --property print.key=true \ --property print.partition=true \ --from-beginning
브로커 정상 전송 여부 확인하는 프로듀셔
java -
ProducerWithAsyncCallbackProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "PangyoKey", "Pangyo"); producer.send(record, new ProducerCallback());java -
ProducerCallbacksend()는 Future 객체를 반환함으로, recordMetadata를 비동기 반환
주의 : 빠르지만, 데이터 순서가 중요하다면.. 동기로 받아
public class ProducerCallback implements Callback { private final static Logger logger = LoggerFactory.getLogger(ProducerCallback.class); @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e != null) logger.error(e.getMessage(), e); else logger.info(recordMetadata.toString()); } }로그 결과
[kafka-producer-network-thread | producer-1] INFO com.example.ProducerCallback - test-1@1RecordMetadata
{토픽이름}-{파티션번호}@{오프셋번호} = test-1@1
3.4.2 컨슈머 API
적재된 데이터를 사용하기 위해 브로커로 부터 데이터를 가져와 필요한 처리.
동일하게 자바 애플리케이션으로 처리부 생성.
컨슈머 그룹
컨슈머 목적 분리
컨슈머가 중단되거나 재시작되어도 컨슈머 그룹의 오프셋 기준으로 데이터 처리.
없으면, 어떤 그룹에도 속하지않은채 동작.
컨슈머 동작 후, 로그 확인
[main] INFO com.example.SimpleConsumer - record:ConsumerRecord( topic = test, partition = 1, leaderEpoch = 0, offset = 2, CreateTime = 1734101735044, serialized key size = 9, serialized value size = 6, headers = RecordHeaders(headers = [], isReadOnly = false), key = PangyoKey, value = Pangyo)소비된 파티션, 오프셋 등을 확인 가능.
leaderEpoch는 현재 리더 파티션의 변경 세대 번호를 의미…→ 리더변경 시, 증가하며 변경여부 확인가능
컨슈머 중요 개념
운영방법
운영 방법은 크게 2가지
- 1개이상의 컨슈머 구성의 컨슈머 그룹 운영
- 특정 파티션만 구독하는 컨슈머 운영
파티션 개수
컨슈머 하나에 여러개 파티션 할당 가능.
컨슈머 개수는 파티션 갯수보다 이하여야함.
→ 유후 상태로 남을 수 있음. (불필요한 스레드)
그룹간 격리
컨슈머 그룹끼리 영향을 받지 않음.
→ 토픽의 데이터 적재나 처리에따라 컨슈머 그룹을 나누자
컨슈머 그룹에 장애가 발생한다면?
문제가 생긴 컨슈머를 제거하는 리밸런싱 됨.
- 리밸런싱 상황
- 컨슈머가 추가되는 상황
- 컨슈머가 제외되는 상황
- 리밸런싱 상황
그룹 조정자
리밸런싱을 발동시키는 역할.
카프카의 브로커 중 한 대가 역할을 수행.
명시/비명시 오프셋 커밋
enable.auto.commit=true를 통해서 일정 간격마다 오프셋을 커밋하도록 할 수 있음.
비명시 오프셋 커밋은 편리하지만, 리밸런싱이나 컨슈머 종료시에 데이터 중복 또는 유실 될 수 있다
commitSync() & commitAsync()
commitSync()
poll()메서드를 통해 반환된 레코드의 가장 마지막 오프셋을 기준으로 커밋 수행
→ 동일 시간당 데이터 처리량이 줄어듬
commitAsync()
비동기 커밋으로 커밋요청이 실패했을 경우, 현재 처리중인 데이터 순서를 보장하지 않음.
컨슈머 주요 옵션
얘도 동일하게 필수옵션/선택옵션의 기본값을 잘 활용하자.
필수 옵션
- bootstrap.servers
- key.serializer
- value.serializer
선택 옵션
group.id
컨슈머 그룹아이디, subscribe()로 토픽 구독하여 사용할때 필수로 넣어야함.
default : null
auto.offset.reset
컨슈머 그룹이 특정파티션을 읽을 때, 저장된 컨슈머 오프셋이 없는 경우 어느 오프셋부터 읽을지에 대한 옵션.
lastest : 가장 최근에 넣은 오프셋부터
earilest : 가장 낮은 오프셋부터
none : 커밋한 기록부터 시작하고 없으면 오류 반환.
default : none
enable.auto.commit
자동 커밋 여부
default : true
auto.cmmit.interval.ms
자동커밋일 경우, 오프셋 커밋 간격
default : 5000(5초)
session.timeout.ms
컨슈머와 브로커와 연결이 끊기는 최대시간.
이시간안에 하트비트를 전송하지 않으면 리밸런싱.
기본적으로 하트비트 시간의 3배로 설정.
⇒ 3배를 사용하는 것은 Kafka 공식 권장 설정. 일시적인 문제를 무시하면서도, 컨슈머의 다운을 빠르게 감지하는 절충안입니다. (네트워크 지연, 일시적 장애에 대한 누락 대비)
default : 10000(10초)
heartbeat.interval.ms
하트비트 전송 시간간격
default : 3000(3초)
max.poll.interval.ms
poll() 메서드를 호출하는 간격의 최대시간.
데이터처리에 너무 많이 걸리면 비정상 판단하여 리밸런싱.
default : 300000(5분)
isolation.level
트랜잭션 프로듀서가 레코드를 트랜잭션 단위로 보낼경우 사용.
read_commited : 커밋이 완료된 레코드만 읽음.
read_uncommitted : 커밋 여부 관계없이 파티션의 모든레코드 읽음
default : read_uncommitted
동기 오프셋 커밋
poll() 메서드 이후에, commitSync() 메서드를 호출하여 오프셋 커밋을 명시적 수행.
java -
ConsumerWithSyncCommit가장 마지막 레코드 오프셋을 기준으로 커밋
consumer.commitSync();java -
ConsumerWithSyncOffsetCommit개별 레코드 단위로 매번 오프셋 커밋하고 싶다
Map<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>(); // 개별 레코드 단위로 매번 오프셋 커밋 for (ConsumerRecord<String, String> record : records) { logger.info("record:{}", record); currentOffset.put( new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, null)); consumer.commitSync(currentOffset); }
비동기 오프셋 커밋
커밋을 기다리기때문에, 데이터처리가 일시적 중단
→ 데이터 처리성을 위해 비동기 오프셋 사용
java -
ConsumerWithASyncCommit비동기로 커밋 응답을 받기에, callBack함수로 결과를 받을 수 있음.
consumer.commitAsync(new OffsetCommitCallback() { public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) { if (e != null) System.err.println("Commit failed"); else System.out.println("Commit succeeded"); if (e != null) logger.error("Commit failed for offsets {}", offsets, e); } });
리밸런스 리스너를 가진 컨슈머
java -
RebalanceListenerConsumerRebalanceListener 인터페이스를 제공하며 사용!
public class RebalanceListener implements ConsumerRebalanceListener { // 리밸런싱을 감지하는 인터페이스 private final static Logger logger = LoggerFactory.getLogger(RebalanceListener.class); public void onPartitionsAssigned(Collection<TopicPartition> partitions) { // 리밸런싱 끝난뒤에 파티션 할당 완료되면 호출 logger.warn("Partitions are assigned : " + partitions.toString()); } public void onPartitionsRevoked(Collection<TopicPartition> partitions) { // 리밸런스 시작되기 직전에 호출 logger.warn("Partitions are revoked : " + partitions.toString()); } }
파티션 할당 컨슈머
java -
ConsumerWithExactPartitionsubscribe() 메서드를 이용하여 구독 형태말고, 직접파티션을 명시하여 사용할 수 있음
assign() 사용.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs); consumer.assign(Collections.singleton(new TopicPartition(TOPIC_NAME, PARTITION_NUMBER)));TopicPartition
카프카 내/외부에서 사용되는 토픽. 파티션 정보를 담는 객체.’
특징
직접 파티션을 할당하기에 리밸런싱 과정없음.
컨슈머에 할당된 파티션 확인
assignment()로 토픽이름과 파티션번호 포함.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs); consumer.subscripbe(Arrays.asList(TOPIC_NAME)); Set<TopciPartition> assginedTopciPartition = consumer.assignment();컨슈머의 안전한 종료
컨슈머 애플리케이션이 정상적으로 종료되지않으면, 컨슈머가 세션 타임아웃이 발생할때까지 컨슈머 그룹에 남음.
→ 컨슈머랙이 늘어나 데이터 처리지연 발생
wakeUp() 메소드
이 메서드가 실행된 후, poll() 메서도 호출되면 WakeupException 발생
이 예외를 받았을 경우, 데이터 처리를 위한 자원들을 해제해야함.
→ close()로 안전하게 종료되었다는 것을 알림.
java -
ConsumerWithSyncOffsetCommit셧다운되면서 wakeup() 호출.
Runtime.getRuntime().addShutdownHook(new ShutdownThread()); try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> record : records) { logger.info("{}", record); } consumer.commitSync(); } } catch (WakeupException e) { logger.warn("Wakeup consumer"); // 리소스 해제 처리 필요 } finally { logger.warn("Consumer close"); consumer.close(); // 안전하게 종료되었다 명시적 } static class ShutdownThread extends Thread { public void run() { logger.info("Shutdown hook"); consumer.wakeup(); } }
3.4.3 어드민 API
내부 옵션을 확인하는 방법.
직접 브로커 들어가서 확인
카프카 커맨드 라인 인터페이스로 명령을 내려 확인
AdminClient 클래스 사용
내부옵션 설정, 조회
예시
- 구독하는 토픽의 파티션 개수만큼 스레드 생성하고 싶을 때, 어드민 API로 확인하여 가져올 수 있음.
- 웹 대시보드를 구현하여 클러스터 접근 권한 규칙 제어가능
- 토픽의 양을 감지하여 파티션을 늘리수있음!
선언
추가 설정없이 클러스터에 대한 정보만 하면 됨.
Properties configs = new Properties(); configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "my-kafka:9092"); AdminClient admin = AdminClient.create(configs); admin.close(); // 명시적 종료주요 메소드
- 브로커 정보 조회
- 토픽 리스트 조회
- 컨슈머 그룹조회
- 신규 토픽 생성
- 파티션 개수 변경
- 접근 제어 규칙 생성
주의점
어드민 API는 클러스터의 버전과 클라이언트의 버전을 맞춰서 사용해야함.
→ 어드민 API는 버전이 올라가며 자주 바뀜
3.5 카프카 스트림즈
토픽에 적재된 데이터를 상태/비상태 기반으로 실시간 변환하여 다른 토픽에 적재하는 라이브러리.
비슷한 오픈소스
아파치 스파크
아파치 플링크
아파치 스톰…
카프카 스트림즈 사용해야하는 이유?
- 자바 라이브러리와 완벽호환(같이 릴리즈)
- 정확히 한번을 구현하는 장애 허용 시스템
프로듀서와 컨슈머의 조합말고 스트림즈를 사용하는이유?
데이터처리, 장애허용등의 특징을 완벽히 구현어려움
스트림즈가 제공못하는 경우만 사용
소스토픽과 싱크토픽의 카프카 클러스터가 다른 경우.
구성
스트림즈 애플리케이션은 내부적으로 스레드 1개이상생성.
스레드는 1개 이상의 테스크
테스크
데이터 처리 최소 단위예시
3개의 파티션으로 이루어진 토픽을 처리하려면 내부의 3개의 태스크.
운영예시
실 운영은 안정적 운영을 위해, 2개이상의 서버로 구성.
카프카 스트림즈 구조 - 토폴로지
토폴로지
2개이상의 노드(프로세서)와 선(스트림)으로 이루어진 집합프로세서
소스 프로세서
데이터 처리를 위해 최초 선언 노드
하나 이상의 토픽에서 데이터 가져옴
스트림 프로세서
다른 프로세서가 반환하는 데이터 처리
싱크 프로세서
특정 카프카 토픽으로 저장하는 스트림즈
최종 종착지
데이터 처리 방식
스트림즈DSL로 구현하는 데이터 처리 예시
메시지 값을 기반으로 토픽 분기
지난 10분간 들어온 데이터 개수 집계
토픽과 다른 토픽의 결합으로 새로운 데이터 생성
프로세서 API로 구현하는 데이터 처리 예시
메시지 값의 종류에따라 토픽을 가변적 전송
일정한 시간 간격으로 데이터 처리
3.5.1 스트림즈DSL
구성
레코드의 흐름을 추상화한 3가지 개념
KStream, KTable, GlobalKTable로 스트림즈DSL에만 국한.
KStream
레코드의 흐름 표현으로 메시지 키와 값으로 이루어짐.
컨슈머로 토픽을 구현하는것과 동일 선상.
KTable
메시지 키를 기준으로 사용.
조회 시, 가장 최신에 추가된 레코드 출력.
GlobalKTable
메시지 키를 기준으로 사용.
KTable의 선언된 토픽은 1개 파티션이 1개의 테스크 할당
GlobalKTable은 모든 파티션 데이터가 각 테스크에 할당되어 사용.
예시
Kstream과 KTABLE이 데이터 조인할떄.
코파티셔닝이 되어있어야함.
코파티셔닝
조인을 하려는 2개의 데이터의 파티션 개수가 동일하고 파티셔닝 전략을 맞추는 작업.
→ 동일한 메시지 키를 가진 데이터는 동일한 태스크로 들어가는 것 보장.
리파티셔닝
코파티셔닝이 되어 있지않다면, 리파티셔닝 과정을 거침.
새로운 토픽에 새로운 케시지 키를 가지도록 재배열 과정.
주의점
스트림즈 애플리케이션의 모든 태스크에 동일하게 사용됨
로컬 스토리징 사용량이 증가
브로커 부하 증가
→ 작은 용량의 데이터만 사용, 데이터가 많으면 리파티셔닝을 통해 KTable사용 권장.
스트림즈DSL 주요 옵션
필수 옵션
- bootstrap.servers
- application.id : 스트림즈 구분을 위한 고유 아이디, 다른 로직을 가진 스트림즈 애플리케이션은 다른 아이디를 가져야함.
선택 옵션
default.key.serde
레코드 메시지 키 직렬/역직렬 클래스 지정.
default : Serdes.ByteArray().getClass().getName()
default.value.serde
레코드 메시지 값 직렬/역직렬 클래스
default : Serdes.ByteArray().getClass().getName()
num.stream.threads
스트림 프로세싱 실행 시 실행될 스레드 개수
default :1
state.dir
rocksDB 저장소가 위치할 디렉토리 지정
rockDB
페이북이 개발한 고성능 key-value DB
스트림즈가 상태기반 데이터 처리를 할때 로컬 저장소로 이용default : tmp/kafka-streams
스트림즈DSL - stream(), to()
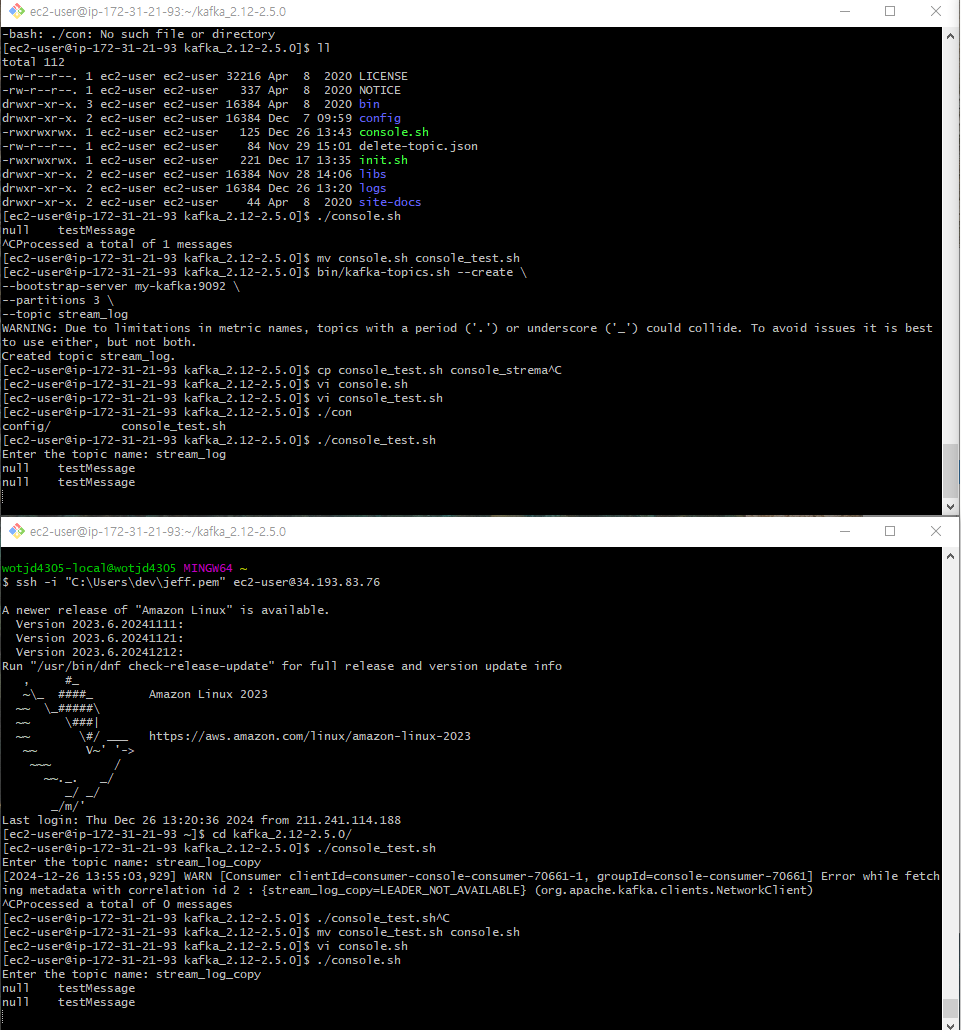
간단하게 토픽의 메세지를 다른토픽으로 전달하는것.
java -
SimpleStreamApplicationstream_log > stream_log_copy로 전달하는 소스
소스프로세서(stream())와 싱크프로세서(to())만 존재.
테스트
토픽생성
bin/kafka-topics.sh --create \ --bootstrap-server my-kafka:9092 \ --partitions 3 \ --topic stream_log콘솔로 stream 확인
기본적인것은 아래로 쉘 생성해서 토픽만입력하도록..
console.sh
```java
#!/bin/bash사용자에게 토픽 이름 입력받기
read -p "Enter the topic name: " topic_name
입력값 검증 (빈 입력 방지)
if [ -z "$topic_name" ]; then
echo "Topic name cannot be empty."
exit 1
fiKafka 소비자 실행
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \
-topic "$topic_name" \
-property print.key=true \
-from-beginning
똑같이 Copy됨을 확인
스트림즈DSL - filter()
필터를 추가하여 데이터 처리 후, 토픽 전달
stream_log > stream_log_filter
java -
StreamsFilterstream_log > stream_log_filter로 전달하는 소스
필터된 상황만 Copy됨을 확인

스트림즈DSL - KTable과 KStream을 join()
데이터베이스에 저장하지 않고도 실시간으로 스트리밍 처리 가능.
자바 -
KStreamJoinKTable토픽생성
KTable
bin/kafka-topics.sh --create \ --bootstrap-server my-kafka:9092 \ --partitions 3 \ --topic addressKStream
bin/kafka-topics.sh --create \ --bootstrap-server my-kafka:9092 \ --partitions 3 \ --topic order조인될 토픽
bin/kafka-topics.sh --create \ --bootstrap-server my-kafka:9092 \ --partitions 3 \ --topic order_joinconsole
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \ --topic order_join \ --property print.key=true \ --property key.separator=":" --from-beginning
조인 확인

스트림즈DSL - GlobalKTable과 KStream을 join()
앞선 사례는 코파티셔닝이 된 상태여서 가능.
java -
KStreamJoinGlobalKTable조인처리
- 리파티셔닝 이후, 코파티셔닝 상태에서 조인
- KTable로 사용하는 토픽을 GlobalKTable로 선언 사용
예시
address_v2라는 토픽을 새로 생성, 파티션 2개로 테스트
→ or
bin/kafka-topics.sh --create \ --bootstrap-server my-kafka:9092 \ --partitions 2 \ --topic address_v2결과 예시
결과물을 보면 KTable과 별반 다르지 않음처럼 보임.

다른점
KStream의 키와 값에도 매칭가능
GlobalKTable으로 선언한 토픽은 태스크마다 저장, 조인
3.5.2 프로세서 api
스트림즈DSL처럼 토폴리지 기준으로 데이터 처리.
추가적인 상세 로직 구현을 위해 사용.
KStream, KTable, GlobalKTable 개념 없음.
자바 -
SimpleKafkaProcessor, FilterProcessor길이가 5이상이면 필터링하여 다른 토픽 저장
토픽 처리
stream_log > 길이 5이상만 > stream_log_filter

3.6 카프카 커넥트
카프카 오픈소스 툴
데이터 파이프라인 생성 시, 반복 작업을 줄이고 효율적 전송을 위한 애플리케이션
특정 작업 형태를 템플릿으로 만들어 놓음
종류
소스 커텍터 : 프로듀서 역할
싱크 커텍터 : 컨슈머 역할
오픈소스 커넥터
jar파일로 S2, JDBC 커넥터등 제공.
컨버터
데이터를 처리하기전 스키마를 변경을 도움
예시
Json컨버터, String컨버터..
트랜스폼
데이터 처리 시, 각 메시지 단위로 변환 가능
커넥트 실행하는 방법
실행
단일 모드 커넥트
1개 프로세스로만, SPOF 발생
분산 모드 커넥트
2개 이상의 커넥트가 클러스터.
Rest API
실행중인 커넥트 정보나, 설정값, 변경요청 가능.
connectors api 참고
단일 모드 커넥트
위치
/config/connect-standalone.properties
파일
bootstrap.servers=localhost:9092 # 커넥트와 연동할 카프카 클러스터 # 카프카 저장/가져올떄 변환에 사용, 스키마형태가 싫으면 false key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true # 데이터 처리 시점, offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000 # 오프셋 커밋 주기 # 플러그인 형태로 추가할 커넥터의 디렉토리 주소 # 콤마로 구분, 오픈소스나 직접개발한 커넥터 jar #plugin.path=파일 소스 커넥터 (connect-file-source.properties)
기본으로 제공하며, 특정 위치에 있는 파일을 읽어서 토픽으로 데이터 저장하는 커넥터.
name=local-file-source connector.class=FileStreamSource # 사용할 커넥터 tasks.max=1 # 태스크 개수, 병렬처리 file=test.txt # 읽을 파일 위치 topic=connect-test # 저장할 토픽 이름실행
파라미터로 커텍트, 커넥터 설정파일을 차례로.
bin/connect-standalone.sh config/connect-standalone.properties \ config/connect-file-source.properties
분산 모드 커텍트
다른 커넥트가 이슈 발생하더라도, 살아있는 나머지가 커넥터를 이어 받아서 파이프라인을 지속적 실행.
위치
/config/connect-distributed.properties
파일
bootstrap.servers=localhost:9092 group.id=connect-cluster # 다수의 커텍트 프로세스들을 묶을 그룹 이름 지정 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true # 내부 토픽 오프셋 처리 시점, 복제개수는 3이상 offset.storage.topic=connect-offsets offset.storage.replication.factor=1 config.storage.topic=connect-configs config.storage.replication.factor=1 status.storage.topic=connect-status status.storage.replication.factor=1 offset.flush.interval.ms=10000 #외부 플러그인. #plugin.path=실행
2대 이상의 분리된 서버에서 서버마다 1개의 분산 모드 커넥트 실행 필요.
bin/connect-distributed.sh config/connect-distributed.properties커넥트 상태 확인
상태, 생성, 조회, 수정, 중단 명령 가능
사용가능한 플러그인 조회.
curl -X GET http://localhost:8083/connector-plugins
커넥터 실행
curl -X POST -H "Content-Type: application/json" \ --data '{ "name": "local-file-source", "config": { "connector.class": "org.apache.kafka.connect.file.FileStreamSourceConnector", "file": "/tmp/test.txt", "tasks.max": "1", "topic": "connect-test" } }' \ http://localhost:8083/connectors커넥터 조회
FileStreamSourceConnector 실행
curl -X GET http://localhost:8083/connectors/local-file-source/status { "name": "local-file-source", "connector": { "state": "RUNNING", "worker_id": "127.0.0.1:8083" }, "tasks": [{ "id": 0, "state": "RUNNING", "worker_id": "127.0.0.1:8083" }], "type": "source" }
3.6.1 소스 커넥터
소스 애플리케이션 or 소스 파일로부터 데이터를 가져와 토픽으로 넣는 역할
오픈소스 소스 커넥터를 사용해도 되지만, 직접 개발해야하는 경우 SourceConnector, SourceTask 클래스를 사용해서 직접 구현.
SourceConnector
커넥터 설정파일을 초기화하고 어떤 태스크 클래스를 사용할지 정의.
데이터 처리부는 없음
public class Test extends SourceConnector { @Override public String version() { // 커넥터 지속적 유지보수를 위함 } @Override public void start(Map<String, String> props) { } // json, config형태로 입력한 값 초기화 @Override public Class<? extends Task> taskClass() { } // 커넥터가 사용할 태스크 클래스 지정 @Override public List<Map<String, String>> taskConfigs(int maxTasks) { } //태스크 개수가 2개이상일 경우, 태스크마다 다른 옵션 @Override public ConfigDef config() { } // 커넥터 사용할 설정값에 대한 정보 @Override public void stop() { } // 커넥터 종료 시 필요한 로직 }SourceTask
소스애플리케이션, 소스 파일 > 토픽 보내는 역할.
자체적은 오프셋을 쓰기에 중복 전송을 방지
public class Test extends SourceTask { @Override public String version() { // 커넥터와 동일하게가 일반 } @Override public void start(Map<String, String> props) { // 테스크 시작시 필요한 로직, 리소스 초기화 // JDBC 소스 커넥터라면 JDBC와 커넥션을 맺음 } @Override public List<SourceRecord> poll() { // 소스파일로 읽으면 SourcesRecord형태로 변환해서 리턴 } @Override public void stop() { // 종료 필요 로직, JDBC 커넥션을 맺었다면 끊는 부분 } }파일 소스 커넥터 구현
카프카 커넥터를 구현할 때에는, 직접 작성한 클래스와 참조 라이브러리도 함꼐 빌드하여 jar로 압축.
→ 없으면 ClassNotFound
java -
SingleFileSourceConnector,SingleFileSourceConnectorConfig,SingleFileSourceTask
3.6.2 싱크 커넥터
토픽 데이터를 타깃 애플리케이션 또는 타깃 파일로 저장하는 역할
SinkConnector
사용자로 받은 입력으로 초기화.
태스크 클래스를 사용할 것인지.
public class TestSinkConnector extends SinkConnector { // 기본적으로 소스 커넥터와 동일 ...SinkTask
실제로 데이터를 처리하는 부분.
public class SingleFileSinkTask extends SinkTask { @Override public String version() { } @Override public void start(Map<String, String> props) { } @Override public void put(Collection<SinkRecord> records) { // 저장할 데이터를 주기적으로 가져오는 부분 } @Override public void flush(Map<TopicPartition, OffsetAndMetadata> offsets) { // put으로 가져온 데이터를 저장할떄 사용하는 로직. // ex) JDBC 커넥터는 put()에서 insert하고 여기서 commit } @Override public void stop() { } }파일 싱크 커넥터 구현
- java -
SingleFileSinkTask, SingleFileSinkConnectorConfig, SingleFileSinkConnector
- java -
3.7 카프카 미러메이커2
서로 다른 두개의 카프카 클러스터 간에 토픽을 복제하는 애플리케이션
필요성
프로듀서와 컨슈머로도 가능하지만, 토픽의 모든것을 복제할 필요가 있을때.
미러메이커1
복제하는 토픽이 달라지면, 미러메이커를 재시작해야했음.
정확히 한번 전달을 보장하지 못하여 데이터 유실 및 중복 가능성.
양방향 토픽 복제 지원 못함.
미러메이커2를 활용한 단반향 토픽 복제
위치
config/connect-mirror-maker.properties
파일
카프카 클러스터 A, 카프카 클러스터 B가 있을 경우를 가정.
clusters = A, B # 토픽이 복제될때 접두사로 붙게 됨, ex) A.chick_log A.bootstrap.servers = a-kafka:9092 # 접속할 클러스터 정보 B.bootstrap.servers = b-kafka:9092 A->B.enabled = true # A->B로 복제할지, 어떤토픽으로할지 A->B.topics = .* B->A.enabled = true B->A.topics = .* replication.factor=1 # 복제되어 신규 생성된 토픽의 복제 개수 ## 토픽 복제에 필요한 데이터를 저장하는 내부 토픽 복제 개수 checkpoints.topic.replication.factor=1 heartbeats.topic.replication.factor=1 offset-syncs.topic.replication.factor=1 offset.storage.replication.factor=1 status.storage.replication.factor=1 config.storage.replication.factor=1 # customize as needed # replication.policy.separator = _ # sync.topic.acls.enabled = false # emit.heartbeats.interval.seconds = 5실행
미러링
bin/connect-mirror-maker.sh config/connect-mirror-maker.propertiesa-kafka 토픽생성
bin/kafka-console-producer.sh --bootstrap-server a-kafka:9092 --topic testb-kafka 콘솔
bin/kafka-console-consumer.sh --bootstrap-server b-kafka:9092 --topic A.test --from-beginning
3.7.1 미러메이커2를 활용할 지리적 복제
카프카 클러스터 단위의 활용도 가능
단방향, 양방향 복제, ACL복제, 새 토픽 자동감지의 기능은 클러스터가 2개 이상일때 빛남.
액티브-스탠바이 클러스터 운영
안정성을 위한 가장좋은 방법은 데이터 센터를 물리적 방식으로 분리하는것.
액티브 > 스탠바이로 복제할때에 랙이 발생하여 스탠바이에 모든정보가 복제되지 않을 수 있음
→ 스탠바이로 전환될 때, 유실,중복 일어날수 있음.
액티브-액티브 클러스터 운영
글로벌 서비스의 경우, 통신지연을 최소화를 위해 2개의 클러스터로 미러링하며 운영할 수 있음.
또한 필요한 데이터만 저장하고 사용할 수 있음.
허브 앤 스포크 클러스터 운영
팀마다 소규머 카프카 클러스터를 이용할때, 한개의 카프카 클러스터로 모아 데이터 레이크로 사용하고 싶을때 사용.
'미들웨어' 카테고리의 다른 글
| 아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (4) (1) | 2025.01.12 |
|---|---|
| 아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (2) (0) | 2024.11.30 |
| 아파치 카프카 - 애플리케이션 프로그래밍 with 자바 (1) (0) | 2024.11.24 |
| 메시지 큐 차이 (Redis Queue, Kafka, RabbitMQ) (0) | 2024.11.10 |

